前言
我的京东价格监控网站需要不间断爬取京东商品页面,爬虫模块我采用了Scrapy+selenium+Headless Chrome的方式进行商品信息的采集。
由于最近爬虫用的服务器到期,需要换到新服务器重新部署,所以干脆把整个模块封装入Docker,以便后续能够方便快速的进行爬虫的部署。同时,由于我的Scrapy整合了redis,能够支持分布式爬取,Docker化后也更方便进行分布式的拓展。
任务需求
- 将爬虫代码打包为Docker镜像
- 在全新的服务器上安装Docker
- 使用单独的Redis容器作为爬取url队列(也就是Scrapy-redis中redis的主要用处)
- 所有新开的爬虫容器连接Redis容器
步骤
打包爬虫代码
Scrapy内置的crawler不支持页面渲染的方式进行页面渲染,需要使用scrapy-splash或者selenium作为中间件,才能够支持页面渲染爬取。我在代码中整合了selenium,并在系统中安装了chrome,这在docker中,需要在打包时将chrome安装至镜像中。
Dockerfile文件中,将chrome下载并安装至镜像,并且将chromedriver放入系统,保证selenium代码能够调用到chrome。
我参考了开源库:https://github.com/joyzoursky/docker-python-chromedriver
最后完成的Dockerfile文件:
1 | FROM python:3.6 |
写完Docker文件,在打包前,最好还要加上.dockerignore避免吧没用的文件打包进镜像。
我打包的代码结构图如下:

使用命令,生成镜像:
1 | sudo docker image build -t pm_scrapy . |
1 | REPOSITORY TAG IMAGE ID CREATED SIZE |
1.41G,大的吓人。
运行redis容器
镜像打包好之后,别急着运行,因为新服务器上,Redis还没有呢。
原则上来说,你可以使用docker-compose,把redis和爬虫代码两个镜像同时运行起来。
我这里,我将redis开启单独的镜像,一是为了方便其它模块使用redis,二是方便以后开更多的scrapy进行分布式爬取。
使用官方的redis镜像开启redis容器,并将redis端口映射到宿主机6379:
1 | docker run -p 6379:6379 -d redis --requirepass "密码" |
官方的redis设置中默认就是0.0.0.0,不用担心宿主机无法访问。
连接爬虫容器和redis容器
接下来可以运行爬虫容器,需要注意的是,连接两个容器,需要使用link。
首先找到redis容器的ID,或者你给他自定义的名字

接着运行并连接容器:
1 | sudo docker container run -itd --link 00c2655515fb:redis pm_scrapy |
出现问题:Docker 使用–link出现Cannot link to /xxx, as it does not belong to xxxxx异常
这个异常的原因是redis在一个特殊的网络里,你需要用:
1 | docker inspect [需要link的容器名称或ID] |
来查看redis容器所在的网段。
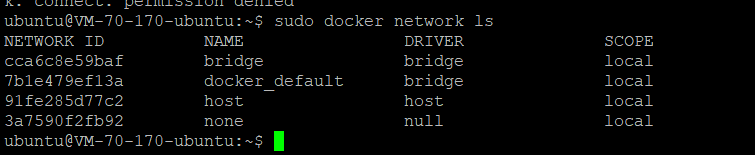
同时还可以看看
1 | docker network ls |
之后你就需要类似这样的语句(多指定–net来定下容器所在网络):
1 | docker run -d --name movie_project -p 9090:80 --link 容器名:别名 --net link_continer_network -v /root/project/movie_project:/app:Z python2/nginx/flask |
参考:
https://blog.csdn.net/hanchaobiao/article/details/81911587
https://www.jianshu.com/p/21d66ca6115e
跑代码
一切就绪,发现爬虫没法运行,使用docker logs 容器ID查看log。发现问题
出现问题:headless chrome:DevToolsActivePort file doesn’t exist while trying to initiate Chrome Browser
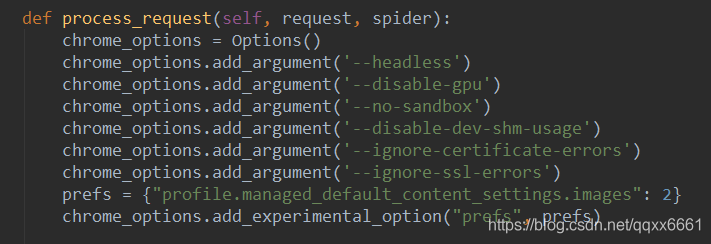
这个问题参考下面的网址,这里直接给出解决方案,在你的代码里加一行参数:
1 | chrome_options.add_argument('--disable-dev-shm-usage') |
这是我的代码截图:
参考:
对该容器的日常维护
平日里可以使用docker exec -it 21323a52d19f /bin/bash进入正在运行容器的bash,查看下爬虫状态
关注我
本人目前为后台开发工程师,主要关注Python爬虫,后台开发等相关技术。
原创博客主要内容:
- 笔试面试复习知识点手册
- Leetcode算法题解析(前150题)
- 剑指offer算法题解析
- Python爬虫相关实战
- 后台开发相关实战
同步更新以下几大博客:
- Csdn:
拥有专栏:Leetcode题解(Java/Python)、Python爬虫开发
- 知乎:
https://www.zhihu.com/people/yang-zhen-dong-1/
拥有专栏:码农面试助攻手册
- 掘金:
https://juejin.im/user/5b48015ce51d45191462ba55
- 简书:
https://www.jianshu.com/u/b5f225ca2376
- 个人公众号:Rude3Knife
